It uses ProjectSpire as the working example: instructions as project memory, plans for intent, Captain Logs for collaboration taste, devlogs for technical history, and skills or workflows for repeated mechanical steps.
The useful idea is that the repo should accumulate context as it is used, so the human still supplies the judgment, but the surrounding system gets better at carrying that judgment forward.
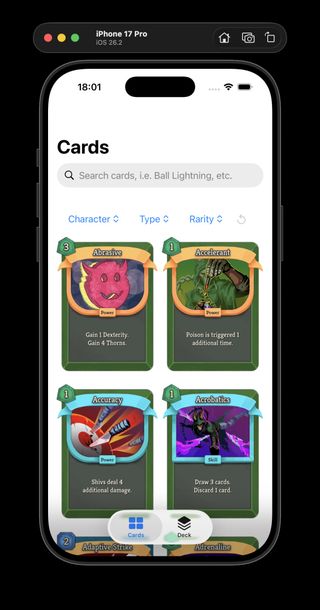
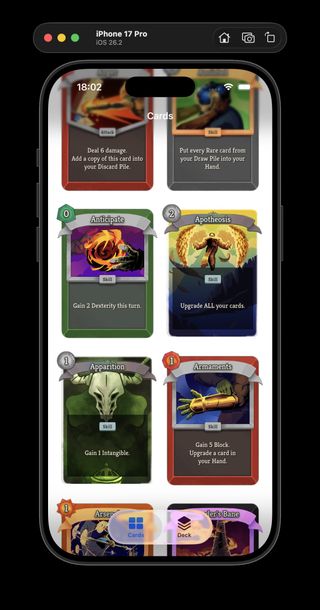
Neow's Cafe browsing catalog-backed card data instead of bundled mock cards.
I spent today turning ProjectSpire's iOS app "Neow's Cafe" from a mock-card browser into something much closer to a real Slay the Spire 2 card catalog.
The main decision was to keep the first version boring in the best way: a static, versioned catalog generated from the game data, served locally, and loaded directly by the app instead of inventing a REST API too early.
That structure gave the app one small index for browsing and filtering, while keeping full per-card files and portrait assets nearby for detail/debug views later. The important bit is that the card grid does not need to fetch hundreds of separate files just to show the collection.
`cards.index.json` is the grid, search, and filter payload. It contains all card summaries needed by the app:
- id
- slug
- title
- description
- energy cost
- type
- rarity
- pool
- portrait path
- optional detail path
Keep individual card JSON files for detail and debug views, not for the main grid.
On the Swift side, CardCatalogService.swift now loads manifest.json, follows it to cards.index.json, and decodes the catalog into app cards. I also removed the old bundled sample portraits, so the app is now much more dependent on the generated catalog behaving like the source of truth.
The Cards screen got some polish too: the catalog can be refreshed from the view, the grid is now a two-column layout that preserves the card aspect ratio in CardsView.swift, and I cleaned up the filter model so "no filter" is represented by optional UI state instead of fake .all enum cases (filter cleanup commit).
The other nice bit from today is process-oriented: ProjectSpire now has Captain Logs for collaboration notes and a reusable workflow for turning a day's commits and documentation changes into these timeline summaries. That should make it easier to keep writing about the work without having to rediscover the shape of the day from raw git history every time.
I added a ProjectSpire design note in 399f74d that pushes the card pipeline toward a two-pass model: keep the parser output source-faithful, then resolve localization and rendered text separately for the app.
I created that work with GPT-5.5 in plan mode, and it asked a few genuinely useful clarification questions before I let it draft anything substantial, which made the whole process feel a lot more controlled than a blind codegen pass. I also pushed back on several of its first suggestions and made a lot of the consequential decisions myself, especially around keeping canonical variable names intact and separating raw data from resolved display data. That feels like a strong pattern for future ProjectSpire work: use the AI models to widen the search space, but keep the architecture decisions and edits grounded in my own judgment.
I split the blog editing rules into repo-local skills in 22c4d7d. post-and-note-workflow now makes the timeline-entry rule explicit, while frontmatter-editing routes posts/, notes/, and timeline/ to canonical front matter docs instead of burying that guidance in CLAUDE.blog.md. I also cleaned up timeline-entry so its tag guidance matches the repo defaults.