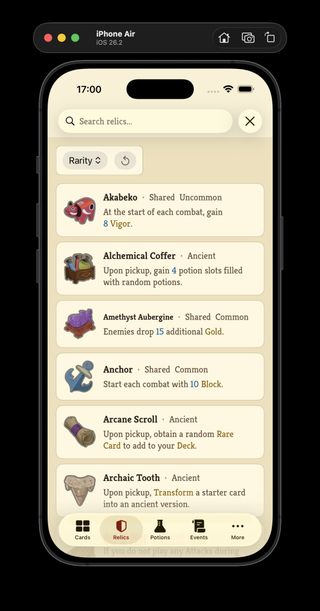
Parsed relic catalog data flowing into the Neow's Cafe relic list and detail views.
I shipped the past couple of days of ProjectSpire work as Neow's Cafe v0.4.0, Catalog Service v0.4.0, and Parser Service v0.3.0. The old card-only parser and catalog names are now broader services, the parsers cover relics, potions, events, and monsters, and Neow's Cafe has live relic list and detail screens backed by the generated catalog instead of mock data. This is the first point where ProjectSpire feels less like a card browser and more like the start of a full Slay the Spire reference app.
The parser now extracts keyword references from card text and populates a keywords field in the generated JSON, which the app picks up and renders as keyword pills on card detail views.
Status and curse cards were the most visibly broken before this: they had no keywords at all, which made a whole class of cards feel incomplete in the UI. The research behind this lives in Lab Doc 0014, which covers how keyword matching works against the game's localization data.
Shipped Card Parser v0.2.3 to ProjectSpire, which adds calculated variable resolution, numeric symbol extraction, and conditional text formatters. Cards like Ashen Strike now show computed damage values instead of raw placeholders, and I've added choose, cond, inverseDiff, and boolean formatters for rendering conditional card text. The parser now threads card type, target type, and runtime display vars (HasRider, Sapping, Energized, etc.) through text resolution, making the pipeline much more precise about card state and context.
The whole card parser has been built in this mode: I act as architect, GPT-5.5 acts as developer. Every meaningful parser improvement came from me inspecting concrete generated JSON against real card examples and asking source-fidelity questions. GPT-5.5 didn't discover that cost upgrades can be negative, or that Bash's upgraded Vulnerable value wasn't being applied, or that X-cost cards needed their own shape. I did, by reading the output and comparing it to what the game actually does.
The pattern that emerged: I'd spot a class of issue on a specific card, explain what the game source was doing and why the output was wrong, and GPT-5.5 would produce a working fix. Then I'd push to turn each discovery into a repeatable check rather than a one-off patch. The coverage audit script, the unresolved placeholder CSV, the hard failures on missing source files: all of those came from me steering toward systemic fixes after catching individual bugs.
What GPT-5.5 is good at in this loop is the mechanical throughput. Regex extraction, threading new state through a resolution pipeline, mirroring changes to the audit script, regenerating 55 JSON files, splitting work into clean commits. The domain knowledge, the quality bar, and the architectural decisions all come from the human side. GPT-5.5 doesn't know what CalculatedVar means in the game engine or why display vars like HasRider matter for conditional text. It doesn't need to, once I describe the shape of the problem clearly enough.
The productivity gain isn't just speed. It's that I can stay at the architectural level, thinking about which cards are still wrong and why, without losing momentum to implementation mechanics. The feedback loop stays tight: inspect, identify, describe, implement, verify, repeat.
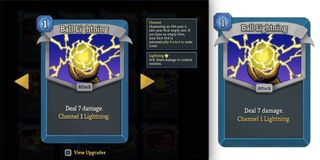
Here's what a fully resolved card looks like now. Ball Lightning's resolved block shows the base and upgraded display states, with structured text runs that carry source variable references and style annotations:
I added a ProjectSpire design note in 399f74d that pushes the card pipeline toward a two-pass model: keep the parser output source-faithful, then resolve localization and rendered text separately for the app.
I created that work with GPT-5.5 in plan mode, and it asked a few genuinely useful clarification questions before I let it draft anything substantial, which made the whole process feel a lot more controlled than a blind codegen pass. I also pushed back on several of its first suggestions and made a lot of the consequential decisions myself, especially around keeping canonical variable names intact and separating raw data from resolved display data. That feels like a strong pattern for future ProjectSpire work: use the AI models to widen the search space, but keep the architecture decisions and edits grounded in my own judgment.
I’ve moved the SwiftUI card view forward by adding a real Card model, so even though the screen does not look dramatically different yet, the app is much closer to rendering cards from extracted data instead of hardcoded values. There is even a small visual regression in the golden text compared with the previous screenshot, but the important change is underneath: I can now refine the card parser and JSON output models, bring those records and required images directly into the app, and aim to emulate any card regardless of rarity, type, or data shape. The relevant work is in the ProjectSpire compare for the card view changes and the new card model.
New Card model version.Previous visual pass for comparison.
I’ve been working since last night and today with agents to document how Slay the Spire 2 works, prototype a Spire API and a REST API on top of it, and shape a WIP card parser that turns C# into JSON structures. That work is captured in ProjectSpire snapshot/2026-04-19, which gives me a concrete snapshot of the game model and tooling so far.